
검색결과 리스트
분류 전체보기에 해당되는 글 98건
- 2008.11.26 Java의 implements, extends 를 C++로 표현하자면? 2
- 2008.11.21 소프트웨어를 제조업으로 보는걸까...? 2
- 2008.11.19 내가 왕년에... 2
- 2008.11.19 WoW 리치킹의 분노가 나온 시점에...
- 2008.11.13 민트패드라...괜찮아보이는걸? 2
- 2008.11.07 About TFC, TFI 1
- 2008.11.05 unix계열의 utility(find같은...)에 좀 더 익숙해져야할텐데 ^^ 5
- 2008.10.24 복잡하고 어려운 문제 풀기 2
- 2008.10.23 야근, 특히 밤새기 금지!! 2
- 2008.10.08 1_CRC Attachment 7
글
Programming 2008. 11. 26. 10:50Java의 implements, extends 를 C++로 표현하자면?
그중에서 좀 애매한 부분이 'implements' 와 'extends'. extends를 구현상속이라고 되어있더라.
C++에선 상속이...그냥 pulic상속이냐, private 상속이냐...이정도만 있어서 뭐가 있나보다...하고 넘어갔다가 오늘 찾아보니 java에서는 좀 상속을 엄격하게 다루는듯.
implements를 C++로 하자면
struct IConnection
{
virtual void connect() = 0;
};
class TCPConnection : public IConnection
{
public:
virtual void connect()
{
어쩌구저쩌구...
}
private:
어쩌구저쩌구...
};
요런식으로 interface만 정의된 (pure virtual function들만 있는...) class를(혹은 구조체를) 상속받아서 구현하는것을 의미한다.
그 외의 것은 다 extends로 보면 된다.
트랙백
댓글
글
잡동사니 2008. 11. 21. 14:03소프트웨어를 제조업으로 보는걸까...?
A : 데이터 개수가 1,5,10,15,30 일때 어떻게 되는지 시뮬레이션 하려고 했으나, 10이상이 될때는 시뮬레이션 기간만 너무 오래 걸려서 30은 못할것 같습니다.
B : 1,5 인건 의미가 없잖아? 15, 30정도는 되야 될꺼같은데.
A : 15정도 되면 2~3일 정도 걸리는 것 같구요, 30되면 정말 오래걸립니다.
B : 뭐야? 5일때 한두시간정도 걸린다며. 그름 15명 3배의 데이터니까 얼마 안걸리고 30도 하루이틀하믄 되잖아?
A : ...오래 걸리더라구요... 좀 힘들것 같습니다.
이 대화를 들으며...참 어이가 없었다. 알고리즘적으로 매우 잘 짜여진 경우에 N log N 이다. 좀 쓸만하면 N의 2승, 대충 테스트용으로 짜는 코드의 경우는 N의 3승 이상이 허다하다. 데이터가 늘어나니 리니어하게 시뮬레이션 시간이 걸릴꺼라고 생각하다뉘...
그리고 그걸로 쪼여도 왜 오래걸리는지 설명못하고 있다뉘....
재밌다 ㅎㅎ 24시간 공장 돌려서 N개가 나오면 48시간 돌리믄 2N개가 나오겠지. 공장이라면...ㅋㅋㅋ
트랙백
댓글
글
잡동사니 2008. 11. 19. 13:20내가 왕년에...
아 물론...'내가 예전엔 이랬고, 지금은 이래' 라고 하는건 또 다르지만. 하지만 뒷말이 안붙은 '내가 왕년에...' 이건 별로 좋아하진않는 편이다. 저 말을 굳이 한번 비꼬자면 지금은 별볼일 없다는 말이니까 ^^
예전에...산업체 시절에 한 부장님이 계셨는데, 기술적인 말을 하면 항상 '내가 예전에 이런걸 만들어봤었는데...' 문제는 그거랑 진행되고 있던 프로젝트랑 별 상관이 없다는것. 그니까...'내가 이런것도 해봤거든? 그러니까 니네덜은 찍소리 말고 내말대로 해' 이거지 뭐.
이글 (링크걸려있슴돠~) 읽다가 그냥...생각나서. ㅎㅎㅎ
뭐 내 주변에서 학위가지고 뽐내는 사람 못봤지만. 혹은 학위로 뽐내는 사람따윈 내가 무시해버려서 기억속에 없을지도 모르겠네. 물론...좋은 학교 간 사람들(서울대나 카이스트 같은곳?) 이랑 이것저것 얘기했을때, 아 좀 똑똑하구나.. 싶은 사람들 있다. 근데 그건 뭐 사람마다 다른거니까. 후광효과가 전혀 없다고는 할 수는 없지만서도.
예를들어 카이스트 나왔다는 사람이 헤매고 있으면 '카이스트라는데 뭐 저러냐-_-' 라는 평가를. 잘하면 '오...역시 좀 잘하는구나'. 첨 들어보는 지방대를 나온 사람이 헤매고 있으면 '쯧...그렇지 뭐'. 요런게 아예 없다고 할 수 있을까.
다만 개발이쪽은, 코드 보면 그 사람의 업무능력이 뻔히 보인다. ㅎㅎㅎ 나름 장점. (혹은 단점 ㅋㅋㅋ)
트랙백
댓글
글
잡동사니 2008. 11. 19. 08:59WoW 리치킹의 분노가 나온 시점에...
와우가 재밌긴하지만...뭐 맨날 밥만 먹고 살 수 있나. 하하하;;
앤솔로지라구 해서...시디 안넣고 해도 되는 버젼이 있고 1.5만원 하길래 옥션에서 하나 샀다.
올만에 베넷 하니까 재밌더만....
비록 3:3 올저그한테 발리긴했지만 ㅡ _-;;;;
그냥 한 30분 시간날때 한두판 즐기기엔 스타크래프트가 참 좋은듯 ^^;;
트랙백
댓글
글
잡동사니 2008. 11. 13. 14:31민트패드라...괜찮아보이는걸?
컨셉이 상당히 괜찮다. 언제나 쓸수있는 메모. 그리고 ad-hoc을 이용한 유저끼리의 통신.
물론 기존의 PDA에서 가능했던 거지만...글쎄? 저런 App들을 이미 탑재하고 있었나?
기능자체는 지원했다. 메모는 메모장 열어서 타이핑(...어느세월에 ㅋ)하면 되고, 유저끼리의 데이터(메모든 뭐든) 전송을 위해서는 ad-hoc 모드를 각자가 켜야되고 (IR을 이용해도 되겠지?) 주위 사람들 검색을 해야되고 이러쿵저러쿵.
하지만 그런것들을 깔끔하게 App로 정리하고, Blog도 쓸수있도록 하고. 충분히 얼리어댑터들의 마음을 뒤흔들어놓을만 하다. 조금 걱정되는건, 제품의 마무리가 iPod touch처럼 고급스러우냐 아니냐, 필기감이 얼마나 좋으냐...정도인데 필기감은 괜찮다는 평들인듯. iPod touch 덕분에 소비자들의 눈은 상당히 높아졌단말이지 ㅎㅎㅎ
사실 내가 햅틱을 폄하하는 이유는, 이름값, 가격 등에 비해 너무 UI 반응이 느리다. (그러나 많이 팔리고 있는듯하다 -_-;;; 대단한 소비자들 ㅎㅎ; 나야 뭐...비싼 핸드폰에 관심이 없으니까 ^^;) 반응이 그냥 예전 PDA와 비슷하다. iPod touch 반응속도의 절반수준도 되지않는다. UI의 깔끔함은 떠나자...어쩔수없다. 그건 UI의 철학이 담겨있는 부분이고 예로부터 Apple의 UI수준은 높기로 유명하지않았나. 그러나 반응속도의 경우는 기술력이다. 철학처럼 수년 이상 쌓여야되는게 아니란말이지 -_-;;
뭐 민트패드 얘기하다가 햅틱,iPod touch로 까지 얘기가 흘러갔는데...어차피 다들 비슷한 부류로 볼 수도 있지않을까 ㅎㅎ 여튼 재밌는 제품이 나왔다는 점에서 반갑고, 컨셉도 훌륭하다!
하지만 난 사지않을듯 -ㅁ-;; 구질구질 큰거 가지고 다니는거 귀찮거든...ㅡ _-;; (덕분에 내 핸드폰도 바형이다. 잠시 팔리고 말았던...기능은 DMB, 외부메모리 등 이것저것 다되지만 DMB가끔 보는거 외에는 전화,문자만 사용중 ㅎㅎㅎ)
트랙백
댓글
글
Programming/WCDMA 2008. 11. 7. 15:00About TFC, TFI
WCDMA for UMTS 책에 보면 간략히 TFI, TFCI의 관계에 대해 나와있다.
TFI는 Transport Format Indicator, TFCI는 Transport Format Combination Indicator의 줄임말이다.
Higher layer에서는 모든 블럭이 Transport Block으로 관리된다. (Transport 채널이기도 하고.) 요 TB들은 어떤 특정한 포맷을 가지게 되는데 이를 TF, Transport Format이라고 한다. 이는 상위에서 설정값으로 내려온다. 이게 종류가 여러개란 말이지. 그런데 physical 전송할때마다 일일히 '이 포맷은 몇바이트짜리다.' 라고 쓰면 bit를 많이 쓰게 되니까 그냥 그걸 index식으로 표현하는게 (0은 A비트, 1은 B비트 뭐 이런식) TFI 인것.
TrCH은 (Transport Channel) 동시에 여러개가 열려있을 수 도 있다. 그러면 당연히 TFI도 여러개. 하지만 실질적으로 Physical Layer의 Channel은 DPCCH, DPDCH의 2개. 그러면 여러개의 TrCH을 Multiplexing 해야되는거지. 그래서 어떤 TFI의 데이터들을 MUX했는지 알려주기 위한 것이 TFCI.
예들 들자면, TrCH이 3개가 있었다고 가정하고 각각 TFI가 0,1,0 이었다고 하자. 저런 구성의 TFI 3개를 섞었을때 TFCI가 0이라고 정해놓는거지. TFI가 0,1,1일 경우에 TFCI가 1이라고 정해놓는거고. 그럼 DPCCH에 TFCI값을 보고 '아 이거 어떤녀석들이 섞여 있는거구나. 그거에 따라서 분리(Demultiplexing)해야겠네' 라고 할 수 있는것.
해당되는 TFCI의 의미를 알려면 3GPP 34.108 의 6.10.2 절을 보면 상세히 나와있다. 저 스펙문서에서 TFS에 보면... '숫자'x'숫자' 가 있다. (ex. 0x103, 1x39, etc) 앞의 숫자는 블럭개수를 의미하고, 뒤의 숫자는 비트수를 의미한다. 간혹 보면 0x103 이런녀석들 있는데...사이즈가 있어도 블럭이 없는것이니까 0이라고 생각하면 된다. (그래서 저런 경우 옆에 'alt. 1x0' 라고 명시되어있다. 사이즈 제로란 소리)
트랙백
댓글
글
잡동사니 2008. 11. 5. 10:06unix계열의 utility(find같은...)에 좀 더 익숙해져야할텐데 ^^
find utility의 철학 요런 글을 발견.
*nix쪽 유틸리티들은...잘 쓰면 좋긴한데...그 잘 쓰기가 참 쉽지않은게 문제 하하하 -ㅁ-;;;
--help 해서 보이는건 극히 일부분이고 (물론 그것만 써도 잘 쓸수있을지도...) 좀 깊게 보려면 man page를 봐야하고, help로 보이는건 거참...불친절하다 ㅎㅎㅎㅎ
그래도 어쩌리...목 마른 사람이 우물을 파야지. 그리고 원래 *nix쪽은 저래왔는걸~~ 내가 익숙해지는 수밖에.
반면 GUI OS 환경에서는 쉽게 다가서기는 좋은 반면...cmd line 기반이 아니라서 자동화하기에는 좀 빡센 측면이 있다. 뭔가 잘 아는걸 하려면 '에이....뭘 이리 클릭질(;;)을 많이 해야되는겨?' 라는거지 ㅎㅎㅎ
command line에 보다 익숙해지기를 바라며...(CUI라고들하지요~)
ps : 근데 이거 링크가 있는 글귀는 글자색을 넣을수가 없네...ㅡ.ㅡ;; 왜그러지?;;;
트랙백
댓글
글
Programming 2008. 10. 24. 15:17복잡하고 어려운 문제 풀기
요즘 회사서 기존 소스코드를 분석하고 있는데...수백줄이 각종 for 문으로 왔다갔다 하는 부분이 있었다. 이거 뭐이리 복잡하나...싶어서 봤더니. 결국 찾아내고 싶은 값은 하나. 각종 전역변수들을 들락날락 했던 이유는? 관계된 값을 찾을 때, index값을 이용하기 때문이었다.
즉 간단히 말해서는 RDB의 모습이었다는것. 뭐 취지는 좋다. index 기반이니까 배열으로써 바로 접근이 가능하니까. 속도면에서도 그럭저럭 쓸만할테고...메모리량도 적게먹을테고. 그러나... 코드가 너무 지저분하며, 검색시에는 해당 값으로 정렬되어있지않기 때문에 무조건 for문을 이용해서 linear하게 찾을 수 밖에 없다. 게다가 테이블에는 유일한 값이 있는것이 아니라 중복값이 있을 수 있다. 즉 for 문 안에서 1번 조건을 만족 하더라도, 2번조건에 부합되지않으면 마저 돌아야되는것. 이러다보니 소스코드가 좀 너저분하고 분기문이 많아진다.
찾는 값들을 살펴보니...3비트, 2비트 길어봐야 16비트 정도의 값이다. 다 합쳐보면 32비트 미만일 듯 싶다. (찾는 값들은 key값들로 볼 수 있고, 나머지 value 값들도 존재함) 이럴 때 사용할 수 있는건 뭔가? DB에서 사용되는 BITMAP Index 를 사용할 수 있지않을까. 그러면 검색하고 싶은 조건을 한번에 32비트안에 다 집어 넣을 수 있을테고 (SQL문의 where 절이 되겠다.) 총 entry 개수만큼 iteration만 하면 100% 검색이 가능하다.
총 entry는 너무 많다고? 그럴수있다. 지금 내가 참여하고있는 프로젝트는 소형 기지국 Femto cell 쪽 SW인데 여기는 총 8명 user에다가 각 유저당 8개의 entry를 가진다. 그럼 여기선 64개의 iteration을 가지지만 64명의 user를 지원한다면? 128번의 iteration이다. 제법 많아지게 되는것이지. 그럴경우? 그럼 유저당 검색을 별개로 할 수 있도록 partitioning을 하면 되는것. 그럴경우 256명을 지원한다고 해봐야 메모리는 좀 더 잡아먹을 수 있겠지만 (그나마도 dynamic allocation을 활용하면 극도로 효율적인 운영이 가능하다.) 속도는 MAX 8번의 iteration만으로 가능해진다.
코드도 보기 좋아지고, 속도도 빨라지고...이 얼마나 좋을소냐. 제발 생각좀 하자...생각좀...
ps : 뭐 사실...생각의 부재라기보다는...Data Structure에 대해서 깊게 공부하는 사람이 없어서 더 이런 문제가 있는 것 같다. 프로그래밍의 가장 중요한 요소인데 말이지...쩝.
ps2 : 어찌보면...DB의 역정규화와 상당히 동일한 작업이다. storage는 조금 더 쓰는 방향이 될듯. (entry들의 사이즈가 작아서 큰 문제는 없다)
트랙백
댓글
글
잡동사니 2008. 10. 23. 14:34야근, 특히 밤새기 금지!!
정말 밤새면 뭐가 문제되는지 실례로 보여준달까;;;
특히나 인상깊었던것은 리플중 하나.
----- 인용 시작 -----
"사람들이 초과 근무를 하는 이유는 과제에 주어진 시간 안에 끝마치기 위해서라기보다는, 일을 정해진 시간까지 끝마치지 못했을 때 비난받게 될 것을 우려해 자신을 보호하기 위함이다" 라는 피플웨어의 얘기가 생각납니다.
----- 인용 끝 -----
피플웨어...도서 이름같은데? 한번 읽어봐야겠구낭...
실제로 OT(OverTime)하는 대다수의 이유는...
1. 위에서 시켜서
2. 능력이 시간에 맞출정도로 대단치 않아서
3. 집에 가기 싫어서
정도가 아닌가. 여기서 1-2번은 관리자의 잘못이고(2번의 경우는 실력도 모른채 일을 맡겼다는 거니까. 일하는 사람의 노력을 안했을수도 있긴하다 ^^;;) 3번은...뭐 집에 가서 애보기 싫거나 그런거지 ㅡ.ㅡ;;;
트랙백
댓글
글
Programming/WCDMA 2008. 10. 8. 10:011_CRC Attachment
1. CRC 란?
CRC라는게 뭔지는 알아야겠지? 일단 비트 계산이 이용된다. 덧셈연산은 XOR(Exclusive OR)가 사용되며 곱셈연산은 AND연산과 동일하다.
영어 위키는 여기. http://en.wikipedia.org/wiki/Cyclic_redundancy_check 잘 정리 되어있다. 간추리자면, 약자 그대로 모든 비트를 검사하고 그걸 축약시켜서 n bit 길이의 code로 만들어 두면, 나중에 실제 message k bits를 보냈을 때, n bit code 검사만으로도 k bit에 Error 가 있는지 없는지 검사할 수 있다는 것. 계산 방법은 영어 위키 페이지에서 Computation of CRC 챕터에 간단히 잘 나와있다.
자 그럼 내가 이 문서를 쓰는 의의는 뭘까?
웹페이지 검색을 해보면 '그냥 이렇게 계산해~' 정도만 나와있다. CRC 원리를 그대로 sw로 구성하면 매우 비효율적이다. 한 비트씩 shift 해서 연산해야되니까. 수백KB가 되면 그거 다 shift하려면 하세월이지. 그런데 SW예제들을 보면 그냥 Table Lookup 방식을 쓴단말이지. 왜 이렇게 해도 되는지는 잘 나와있지않다. 생각해보자. 원리는 bit shifting을 통해서 해야된다고 나와있는데, 실제 구현은 table lookup. 왜 table lookup을 써도 괜찮은지에 대한 설명을 찾기가 쉽지않다. (물론 아주 어려운건 아니다. 그러니까 내가 찾았지 -_-;;) 그래서 table lookup을 쓸 수 있는 이유를 증명을 통해 보이려고 한다. 사실 증명은 문서로 이미 되어있거든. 지금 쓰는건 단지 그것을 이해하고 쉽게 '한글로' 풀어쓰려는 것일뿐. 그 이상도 그 이하도 아니다.
2. CRC 계산 기본
SW 구현을 이해하려면 기본적으로 CRC 계산 수식들에 익숙해져야한다. (CRC가 어떻게 Error Detection을 하고, 제대로 하는것인지에 대한 증명은 패스. 그냥 기본적인 것만 한다.)
CRC 계산을 위해 generator polynomial이 주어지게 되는데 그걸 g(x)라고들 표현한다. (위에 위키 페이지에 보면 잔뜩있는 CRC-8, CRC-16 등등에 사용되는 수식들임) 그리고 입력에 사용되는 k-bit message를 u(x), message에 CRC정보를 덧붙여서 만든 n-bit codeword를 v(x)라고 한다. 그리고, CRC로 붙는 (n-k) bit 내용을 s(x)라고 하자. 요런 관계를 수식으로 표현하면
(1)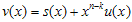
로 표현할 수 있다. 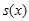 는
는 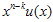 를
를 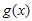 로 나눈 후 나머지가 되는 임의의 다항식이라고 가정하면,
로 나눈 후 나머지가 되는 임의의 다항식이라고 가정하면,
(2) 
라고 가정이 가능하다. (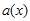 도 역시 임의의 다항식) 이런 상황이 만족되는 경우, 덧셈연산이 XOR이므로
도 역시 임의의 다항식) 이런 상황이 만족되는 경우, 덧셈연산이 XOR이므로 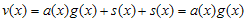 가 된다. 그러므로 v(x)는 g(x)로 나눠떨어지는 값을 가지게 된다. 즉, Error Detect측에서는 단순히 정해진 g(x)로 나눠서 나머지가 없으면 error가 없는 것이라고 판단하는 것이다.
가 된다. 그러므로 v(x)는 g(x)로 나눠떨어지는 값을 가지게 된다. 즉, Error Detect측에서는 단순히 정해진 g(x)로 나눠서 나머지가 없으면 error가 없는 것이라고 판단하는 것이다.
참쉽죠? ^________^
…. 라고 하면 맞으려나? -_-; 사실 수학에 손땐지 오래인 나로써는 쉬워보이면서도 이해하기 어렵더라. 근데 알고보면 별 거 아니다. 솔직히 (1)방정식의 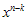 가 어디서 나온건지 궁금해 할 수 있다. (철저히 개인적이다. 뭐…내가 쓰는건데 개인적으로 쓰는거지 ㅡ,.ㅡ) 아까 젤 위에 가정을 할 때 k는 original message의 길이, n은 CRC정보가 첨부된 길이라고 했다. 즉, 항상 n>k 임을 알 수 있다.
가 어디서 나온건지 궁금해 할 수 있다. (철저히 개인적이다. 뭐…내가 쓰는건데 개인적으로 쓰는거지 ㅡ,.ㅡ) 아까 젤 위에 가정을 할 때 k는 original message의 길이, n은 CRC정보가 첨부된 길이라고 했다. 즉, 항상 n>k 임을 알 수 있다. 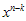 요거는 단지 u(x)의 k승수를 v(x)의 n승수로 맞춰주기 위해 곱해주는 것 일뿐~ 뭐 이것만 알면 아래에 SW구현 파트는 이해가 가능하다.
요거는 단지 u(x)의 k승수를 v(x)의 n승수로 맞춰주기 위해 곱해주는 것 일뿐~ 뭐 이것만 알면 아래에 SW구현 파트는 이해가 가능하다.
이 챕터를 끝내기 전에 예제를 한번 풀어보자.
101011 이라는 bit sequence의 CRC값을 계산하자. 이 경우 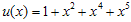 이다. g(x)의 경우 CRC-16으로 하기로하면
이다. g(x)의 경우 CRC-16으로 하기로하면 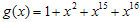 이 된다. 계산하면
이 된다. 계산하면
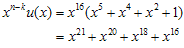
이고 여기에서 s(x)를 계산하면 Figure 3과 같이 된다.
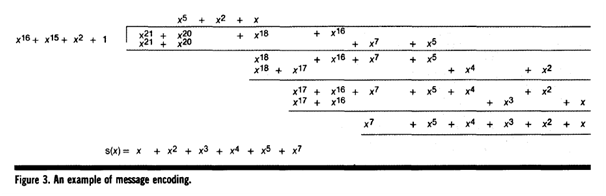
즉, 101011을 CRC-16을 거치면 0111110100000000101011 이 된다.
3. SW 구현
위에서 말했다시피 HW 구현은 그냥 CRC 원리 그대로 bit 계산으로 하면 된다고 치자. (물론 더 좋은 방법으로 구현들 할꺼다…하지만 HW는 내 알바 아니니 패스) SW으로 그렇게 구현하려면 무지 비효율적인것도 이미 말했으니…바로 어떤식으로 계산하면 좋을지 수식으로 들어가자.
CRC generator polynominal을 g(x)로 표현하기로 하고 예제로는 CRC-16을 사용한다고 가정하자. u(x)는 message bits를, s(x)는 g(x)로 나눈 나머지를 의미한다고 가정하자. 그러면…
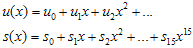
으로 표현이 가능하다. 그리고
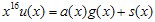
로 가정한다. 자 이제 한 바이트, 즉 8비트가 밀려들어왔다고 가정하자. 새로운 값이 추가된 meesage를 u'(x) 라고 가정하면,
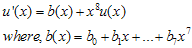
이다. 새로운 나머지값인 s'(x)는
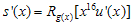
로 표현 할 수 있다. (R은 나머지값이라는 표현임. 다른 뜻은 없으니 크게 신경쓰지말자~) 자~ 식을 전개해보면
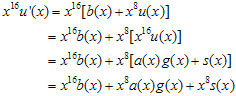
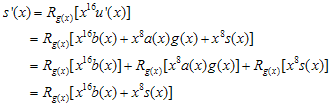
b(x)와 s(x)를 전개해보면
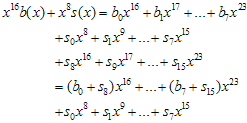
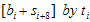 , i = 0,1, … , 7 로 변환시키면
, i = 0,1, … , 7 로 변환시키면
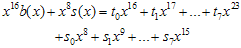
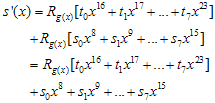
요렇게 된다. g(x)가 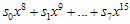 이것보다 큰 값이니까 나머지해봐야
이것보다 큰 값이니까 나머지해봐야 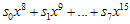 그대로 남는 것이고…자, 8비트 추가된 후의 나머지(CRC)값의 방정식이 구해졌다. 살펴보도록 하자.
그대로 남는 것이고…자, 8비트 추가된 후의 나머지(CRC)값의 방정식이 구해졌다. 살펴보도록 하자.
일단 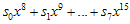 의미는 뭘까?
의미는 뭘까? 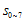 은 8비트 추가가 되기 전에 기존 CRC값의 high-order 8비트값이었다. 그런데 그게 단순히 8비트 right-shift 된 것이지. (x의 승수가 높을수록 low-order bit이다. 위에서 예제로 계산했던 것을 다시 살펴보자)
은 8비트 추가가 되기 전에 기존 CRC값의 high-order 8비트값이었다. 그런데 그게 단순히 8비트 right-shift 된 것이지. (x의 승수가 높을수록 low-order bit이다. 위에서 예제로 계산했던 것을 다시 살펴보자)
이번엔 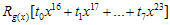 요녀석을 살펴보자. 여기서
요녀석을 살펴보자. 여기서 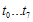 은 단순히 새로 추가된 8비트
은 단순히 새로 추가된 8비트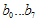 와 기존 u(x)의 하위16비트(CRC-16이니까)에서의 low-order 8bit인
와 기존 u(x)의 하위16비트(CRC-16이니까)에서의 low-order 8bit인 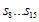 와의 합(XOR)이다. 결론은 꼭 1비트씩 할 필요없이 8비트씩 계산해도 괜찮다~라는것!!
와의 합(XOR)이다. 결론은 꼭 1비트씩 할 필요없이 8비트씩 계산해도 괜찮다~라는것!!
여기서는 8비트씩 계산을 해도 된다~ 라는 결론만 가지고 다음 챕터로 넘어가보자.
4. Table Lookup Algorithm
위에서 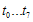 이 값은 8비트이므로 총 256개의 값을 가질 수 있고, 따라서
이 값은 8비트이므로 총 256개의 값을 가질 수 있고, 따라서 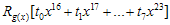 이 값은 미리계산 되어질 수 있다. (영어로 하자면 precomputable하다…정도? 모든 경우의 수를 다 계산해 놓는것) g(x)가 CRC-16의 경우
이 값은 미리계산 되어질 수 있다. (영어로 하자면 precomputable하다…정도? 모든 경우의 수를 다 계산해 놓는것) g(x)가 CRC-16의 경우 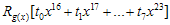 값은 최대 16비트값을 가지게 되므로 해당 테이블의 크기는 2byte * 256 = 512byte가 되겠다. CRC-8이라면 256byte를 가질 것이다. 계산 순서는 다음과 같다.
값은 최대 16비트값을 가지게 되므로 해당 테이블의 크기는 2byte * 256 = 512byte가 되겠다. CRC-8이라면 256byte를 가질 것이다. 계산 순서는 다음과 같다.
- CRC register를 0x0000 으로 만든다. (
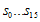 값이다)
값이다) 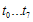 를 구한다. (
를 구한다. (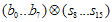 계산)
계산) - CRC register를 8비트 right-shift한다.
- 미리 계산해둔 CRC Lookup table에서 해당
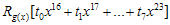 값을 CRC register에 XOR 연산을 한다.
값을 CRC register에 XOR 연산을 한다. - CRC 계산할 byte-stream data가 끝날때까지 2~4 단계를 반복한다.
끝나고 나면 CRC register에 전체 byte-stream data에 대한 CRC 값이 있게된다. 끝!!
5. Reference
A Tutorial on CRC Computations
Ramabadran, T.V. Gaitonde, S.S.
lowa State Univ., Ames, IA
 1_CRC.pdf
1_CRC.pdf
RECENT COMMENT