1. CRC 란?
CRC라는게 뭔지는 알아야겠지? 일단 비트 계산이 이용된다. 덧셈연산은 XOR(Exclusive OR)가 사용되며 곱셈연산은 AND연산과 동일하다.
영어 위키는 여기. http://en.wikipedia.org/wiki/Cyclic_redundancy_check 잘 정리 되어있다. 간추리자면, 약자 그대로 모든 비트를 검사하고 그걸 축약시켜서 n bit 길이의 code로 만들어 두면, 나중에 실제 message k bits를 보냈을 때, n bit code 검사만으로도 k bit에 Error 가 있는지 없는지 검사할 수 있다는 것. 계산 방법은 영어 위키 페이지에서 Computation of CRC 챕터에 간단히 잘 나와있다.
자 그럼 내가 이 문서를 쓰는 의의는 뭘까?
웹페이지 검색을 해보면 '그냥 이렇게 계산해~' 정도만 나와있다. CRC 원리를 그대로 sw로 구성하면 매우 비효율적이다. 한 비트씩 shift 해서 연산해야되니까. 수백KB가 되면 그거 다 shift하려면 하세월이지. 그런데 SW예제들을 보면 그냥 Table Lookup 방식을 쓴단말이지. 왜 이렇게 해도 되는지는 잘 나와있지않다. 생각해보자. 원리는 bit shifting을 통해서 해야된다고 나와있는데, 실제 구현은 table lookup. 왜 table lookup을 써도 괜찮은지에 대한 설명을 찾기가 쉽지않다. (물론 아주 어려운건 아니다. 그러니까 내가 찾았지 -_-;;) 그래서 table lookup을 쓸 수 있는 이유를 증명을 통해 보이려고 한다. 사실 증명은 문서로 이미 되어있거든. 지금 쓰는건 단지 그것을 이해하고 쉽게 '한글로' 풀어쓰려는 것일뿐. 그 이상도 그 이하도 아니다.
2. CRC 계산 기본
SW 구현을 이해하려면 기본적으로 CRC 계산 수식들에 익숙해져야한다. (CRC가 어떻게 Error Detection을 하고, 제대로 하는것인지에 대한 증명은 패스. 그냥 기본적인 것만 한다.)
CRC 계산을 위해 generator polynomial이 주어지게 되는데 그걸 g(x)라고들 표현한다. (위에 위키 페이지에 보면 잔뜩있는 CRC-8, CRC-16 등등에 사용되는 수식들임) 그리고 입력에 사용되는 k-bit message를 u(x), message에 CRC정보를 덧붙여서 만든 n-bit codeword를 v(x)라고 한다. 그리고, CRC로 붙는 (n-k) bit 내용을 s(x)라고 하자. 요런 관계를 수식으로 표현하면
(1)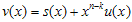
로 표현할 수 있다. 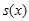 는
는 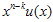 를
를 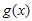 로 나눈 후 나머지가 되는 임의의 다항식이라고 가정하면,
로 나눈 후 나머지가 되는 임의의 다항식이라고 가정하면,
(2) 
라고 가정이 가능하다. (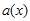 도 역시 임의의 다항식) 이런 상황이 만족되는 경우, 덧셈연산이 XOR이므로
도 역시 임의의 다항식) 이런 상황이 만족되는 경우, 덧셈연산이 XOR이므로 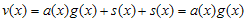 가 된다. 그러므로 v(x)는 g(x)로 나눠떨어지는 값을 가지게 된다. 즉, Error Detect측에서는 단순히 정해진 g(x)로 나눠서 나머지가 없으면 error가 없는 것이라고 판단하는 것이다.
가 된다. 그러므로 v(x)는 g(x)로 나눠떨어지는 값을 가지게 된다. 즉, Error Detect측에서는 단순히 정해진 g(x)로 나눠서 나머지가 없으면 error가 없는 것이라고 판단하는 것이다.
참쉽죠? ^________^
…. 라고 하면 맞으려나? -_-; 사실 수학에 손땐지 오래인 나로써는 쉬워보이면서도 이해하기 어렵더라. 근데 알고보면 별 거 아니다. 솔직히 (1)방정식의 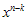 가 어디서 나온건지 궁금해 할 수 있다. (철저히 개인적이다. 뭐…내가 쓰는건데 개인적으로 쓰는거지 ㅡ,.ㅡ) 아까 젤 위에 가정을 할 때 k는 original message의 길이, n은 CRC정보가 첨부된 길이라고 했다. 즉, 항상 n>k 임을 알 수 있다.
가 어디서 나온건지 궁금해 할 수 있다. (철저히 개인적이다. 뭐…내가 쓰는건데 개인적으로 쓰는거지 ㅡ,.ㅡ) 아까 젤 위에 가정을 할 때 k는 original message의 길이, n은 CRC정보가 첨부된 길이라고 했다. 즉, 항상 n>k 임을 알 수 있다. 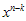 요거는 단지 u(x)의 k승수를 v(x)의 n승수로 맞춰주기 위해 곱해주는 것 일뿐~ 뭐 이것만 알면 아래에 SW구현 파트는 이해가 가능하다.
요거는 단지 u(x)의 k승수를 v(x)의 n승수로 맞춰주기 위해 곱해주는 것 일뿐~ 뭐 이것만 알면 아래에 SW구현 파트는 이해가 가능하다.
이 챕터를 끝내기 전에 예제를 한번 풀어보자.
101011 이라는 bit sequence의 CRC값을 계산하자. 이 경우 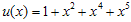 이다. g(x)의 경우 CRC-16으로 하기로하면
이다. g(x)의 경우 CRC-16으로 하기로하면 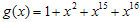 이 된다. 계산하면
이 된다. 계산하면
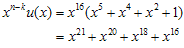
이고 여기에서 s(x)를 계산하면 Figure 3과 같이 된다.
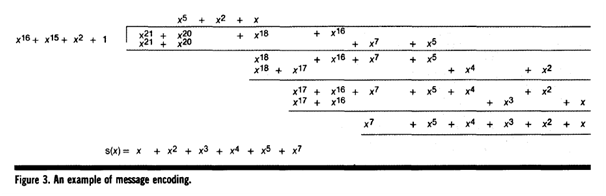
즉, 101011을 CRC-16을 거치면 0111110100000000101011 이 된다.
3. SW 구현
위에서 말했다시피 HW 구현은 그냥 CRC 원리 그대로 bit 계산으로 하면 된다고 치자. (물론 더 좋은 방법으로 구현들 할꺼다…하지만 HW는 내 알바 아니니 패스) SW으로 그렇게 구현하려면 무지 비효율적인것도 이미 말했으니…바로 어떤식으로 계산하면 좋을지 수식으로 들어가자.
CRC generator polynominal을 g(x)로 표현하기로 하고 예제로는 CRC-16을 사용한다고 가정하자. u(x)는 message bits를, s(x)는 g(x)로 나눈 나머지를 의미한다고 가정하자. 그러면…
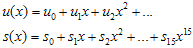
으로 표현이 가능하다. 그리고
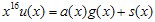
로 가정한다. 자 이제 한 바이트, 즉 8비트가 밀려들어왔다고 가정하자. 새로운 값이 추가된 meesage를 u'(x) 라고 가정하면,
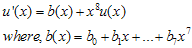
이다. 새로운 나머지값인 s'(x)는
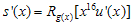
로 표현 할 수 있다. (R은 나머지값이라는 표현임. 다른 뜻은 없으니 크게 신경쓰지말자~) 자~ 식을 전개해보면
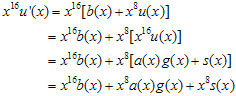
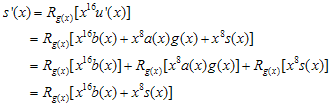
b(x)와 s(x)를 전개해보면
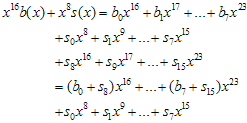
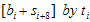 , i = 0,1, … , 7 로 변환시키면
, i = 0,1, … , 7 로 변환시키면
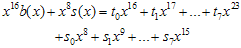
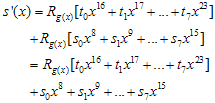
요렇게 된다. g(x)가 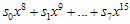 이것보다 큰 값이니까 나머지해봐야
이것보다 큰 값이니까 나머지해봐야 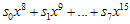 그대로 남는 것이고…자, 8비트 추가된 후의 나머지(CRC)값의 방정식이 구해졌다. 살펴보도록 하자.
그대로 남는 것이고…자, 8비트 추가된 후의 나머지(CRC)값의 방정식이 구해졌다. 살펴보도록 하자.
일단 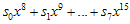 의미는 뭘까?
의미는 뭘까? 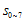 은 8비트 추가가 되기 전에 기존 CRC값의 high-order 8비트값이었다. 그런데 그게 단순히 8비트 right-shift 된 것이지. (x의 승수가 높을수록 low-order bit이다. 위에서 예제로 계산했던 것을 다시 살펴보자)
은 8비트 추가가 되기 전에 기존 CRC값의 high-order 8비트값이었다. 그런데 그게 단순히 8비트 right-shift 된 것이지. (x의 승수가 높을수록 low-order bit이다. 위에서 예제로 계산했던 것을 다시 살펴보자)
이번엔 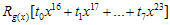 요녀석을 살펴보자. 여기서
요녀석을 살펴보자. 여기서 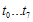 은 단순히 새로 추가된 8비트
은 단순히 새로 추가된 8비트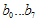 와 기존 u(x)의 하위16비트(CRC-16이니까)에서의 low-order 8bit인
와 기존 u(x)의 하위16비트(CRC-16이니까)에서의 low-order 8bit인 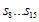 와의 합(XOR)이다. 결론은 꼭 1비트씩 할 필요없이 8비트씩 계산해도 괜찮다~라는것!!
와의 합(XOR)이다. 결론은 꼭 1비트씩 할 필요없이 8비트씩 계산해도 괜찮다~라는것!!
여기서는 8비트씩 계산을 해도 된다~ 라는 결론만 가지고 다음 챕터로 넘어가보자.
4. Table Lookup Algorithm
위에서 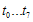 이 값은 8비트이므로 총 256개의 값을 가질 수 있고, 따라서
이 값은 8비트이므로 총 256개의 값을 가질 수 있고, 따라서 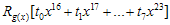 이 값은 미리계산 되어질 수 있다. (영어로 하자면 precomputable하다…정도? 모든 경우의 수를 다 계산해 놓는것) g(x)가 CRC-16의 경우
이 값은 미리계산 되어질 수 있다. (영어로 하자면 precomputable하다…정도? 모든 경우의 수를 다 계산해 놓는것) g(x)가 CRC-16의 경우 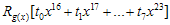 값은 최대 16비트값을 가지게 되므로 해당 테이블의 크기는 2byte * 256 = 512byte가 되겠다. CRC-8이라면 256byte를 가질 것이다. 계산 순서는 다음과 같다.
값은 최대 16비트값을 가지게 되므로 해당 테이블의 크기는 2byte * 256 = 512byte가 되겠다. CRC-8이라면 256byte를 가질 것이다. 계산 순서는 다음과 같다.
- CRC register를 0x0000 으로 만든다. (
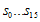 값이다)
값이다)
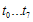 를 구한다. (
를 구한다. (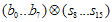 계산)
계산) - CRC register를 8비트 right-shift한다.
- 미리 계산해둔 CRC Lookup table에서 해당
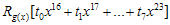 값을 CRC register에 XOR 연산을 한다.
값을 CRC register에 XOR 연산을 한다.
- CRC 계산할 byte-stream data가 끝날때까지 2~4 단계를 반복한다.
끝나고 나면 CRC register에 전체 byte-stream data에 대한 CRC 값이 있게된다. 끝!!
5. Reference
A Tutorial on CRC Computations
Ramabadran, T.V. Gaitonde, S.S.
lowa State Univ., Ames, IA
 1_CRC.pdf
1_CRC.pdf