생각을 깊게하면 좀 더 난이도를 낮출 수 있다!!
요즘 회사서 기존 소스코드를 분석하고 있는데...수백줄이 각종 for 문으로 왔다갔다 하는 부분이 있었다. 이거 뭐이리 복잡하나...싶어서 봤더니. 결국 찾아내고 싶은 값은 하나. 각종 전역변수들을 들락날락 했던 이유는? 관계된 값을 찾을 때, index값을 이용하기 때문이었다.
즉 간단히 말해서는 RDB의 모습이었다는것. 뭐 취지는 좋다. index 기반이니까 배열으로써 바로 접근이 가능하니까. 속도면에서도 그럭저럭 쓸만할테고...메모리량도 적게먹을테고. 그러나... 코드가 너무 지저분하며, 검색시에는 해당 값으로 정렬되어있지않기 때문에 무조건 for문을 이용해서 linear하게 찾을 수 밖에 없다. 게다가 테이블에는 유일한 값이 있는것이 아니라 중복값이 있을 수 있다. 즉 for 문 안에서 1번 조건을 만족 하더라도, 2번조건에 부합되지않으면 마저 돌아야되는것. 이러다보니 소스코드가 좀 너저분하고 분기문이 많아진다.
찾는 값들을 살펴보니...3비트, 2비트 길어봐야 16비트 정도의 값이다. 다 합쳐보면 32비트 미만일 듯 싶다. (찾는 값들은 key값들로 볼 수 있고, 나머지 value 값들도 존재함) 이럴 때 사용할 수 있는건 뭔가? DB에서 사용되는 BITMAP Index 를 사용할 수 있지않을까. 그러면 검색하고 싶은 조건을 한번에 32비트안에 다 집어 넣을 수 있을테고 (SQL문의 where 절이 되겠다.) 총 entry 개수만큼 iteration만 하면 100% 검색이 가능하다.
총 entry는 너무 많다고? 그럴수있다. 지금 내가 참여하고있는 프로젝트는 소형 기지국 Femto cell 쪽 SW인데 여기는 총 8명 user에다가 각 유저당 8개의 entry를 가진다. 그럼 여기선 64개의 iteration을 가지지만 64명의 user를 지원한다면? 128번의 iteration이다. 제법 많아지게 되는것이지. 그럴경우? 그럼 유저당 검색을 별개로 할 수 있도록 partitioning을 하면 되는것. 그럴경우 256명을 지원한다고 해봐야 메모리는 좀 더 잡아먹을 수 있겠지만 (그나마도 dynamic allocation을 활용하면 극도로 효율적인 운영이 가능하다.) 속도는 MAX 8번의 iteration만으로 가능해진다.
코드도 보기 좋아지고, 속도도 빨라지고...이 얼마나 좋을소냐. 제발 생각좀 하자...생각좀...
ps : 뭐 사실...생각의 부재라기보다는...Data Structure에 대해서 깊게 공부하는 사람이 없어서 더 이런 문제가 있는 것 같다. 프로그래밍의 가장 중요한 요소인데 말이지...쩝.
ps2 : 어찌보면...DB의 역정규화와 상당히 동일한 작업이다. storage는 조금 더 쓰는 방향이 될듯. (entry들의 사이즈가 작아서 큰 문제는 없다)
요즘 회사서 기존 소스코드를 분석하고 있는데...수백줄이 각종 for 문으로 왔다갔다 하는 부분이 있었다. 이거 뭐이리 복잡하나...싶어서 봤더니. 결국 찾아내고 싶은 값은 하나. 각종 전역변수들을 들락날락 했던 이유는? 관계된 값을 찾을 때, index값을 이용하기 때문이었다.
즉 간단히 말해서는 RDB의 모습이었다는것. 뭐 취지는 좋다. index 기반이니까 배열으로써 바로 접근이 가능하니까. 속도면에서도 그럭저럭 쓸만할테고...메모리량도 적게먹을테고. 그러나... 코드가 너무 지저분하며, 검색시에는 해당 값으로 정렬되어있지않기 때문에 무조건 for문을 이용해서 linear하게 찾을 수 밖에 없다. 게다가 테이블에는 유일한 값이 있는것이 아니라 중복값이 있을 수 있다. 즉 for 문 안에서 1번 조건을 만족 하더라도, 2번조건에 부합되지않으면 마저 돌아야되는것. 이러다보니 소스코드가 좀 너저분하고 분기문이 많아진다.
찾는 값들을 살펴보니...3비트, 2비트 길어봐야 16비트 정도의 값이다. 다 합쳐보면 32비트 미만일 듯 싶다. (찾는 값들은 key값들로 볼 수 있고, 나머지 value 값들도 존재함) 이럴 때 사용할 수 있는건 뭔가? DB에서 사용되는 BITMAP Index 를 사용할 수 있지않을까. 그러면 검색하고 싶은 조건을 한번에 32비트안에 다 집어 넣을 수 있을테고 (SQL문의 where 절이 되겠다.) 총 entry 개수만큼 iteration만 하면 100% 검색이 가능하다.
총 entry는 너무 많다고? 그럴수있다. 지금 내가 참여하고있는 프로젝트는 소형 기지국 Femto cell 쪽 SW인데 여기는 총 8명 user에다가 각 유저당 8개의 entry를 가진다. 그럼 여기선 64개의 iteration을 가지지만 64명의 user를 지원한다면? 128번의 iteration이다. 제법 많아지게 되는것이지. 그럴경우? 그럼 유저당 검색을 별개로 할 수 있도록 partitioning을 하면 되는것. 그럴경우 256명을 지원한다고 해봐야 메모리는 좀 더 잡아먹을 수 있겠지만 (그나마도 dynamic allocation을 활용하면 극도로 효율적인 운영이 가능하다.) 속도는 MAX 8번의 iteration만으로 가능해진다.
코드도 보기 좋아지고, 속도도 빨라지고...이 얼마나 좋을소냐. 제발 생각좀 하자...생각좀...
ps : 뭐 사실...생각의 부재라기보다는...Data Structure에 대해서 깊게 공부하는 사람이 없어서 더 이런 문제가 있는 것 같다. 프로그래밍의 가장 중요한 요소인데 말이지...쩝.
ps2 : 어찌보면...DB의 역정규화와 상당히 동일한 작업이다. storage는 조금 더 쓰는 방향이 될듯. (entry들의 사이즈가 작아서 큰 문제는 없다)
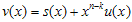
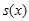 는
는 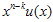 를
를 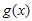 로 나눈 후 나머지가 되는 임의의 다항식이라고 가정하면,
로 나눈 후 나머지가 되는 임의의 다항식이라고 가정하면, 
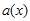 도 역시 임의의 다항식) 이런 상황이 만족되는 경우, 덧셈연산이 XOR이므로
도 역시 임의의 다항식) 이런 상황이 만족되는 경우, 덧셈연산이 XOR이므로 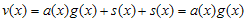 가 된다. 그러므로 v(x)는 g(x)로 나눠떨어지는 값을 가지게 된다. 즉, Error Detect측에서는 단순히 정해진 g(x)로 나눠서 나머지가 없으면 error가 없는 것이라고 판단하는 것이다.
가 된다. 그러므로 v(x)는 g(x)로 나눠떨어지는 값을 가지게 된다. 즉, Error Detect측에서는 단순히 정해진 g(x)로 나눠서 나머지가 없으면 error가 없는 것이라고 판단하는 것이다. 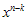 가 어디서 나온건지 궁금해 할 수 있다. (철저히 개인적이다. 뭐…내가 쓰는건데 개인적으로 쓰는거지 ㅡ,.ㅡ) 아까 젤 위에 가정을 할 때 k는 original message의 길이, n은 CRC정보가 첨부된 길이라고 했다. 즉, 항상 n>k 임을 알 수 있다.
가 어디서 나온건지 궁금해 할 수 있다. (철저히 개인적이다. 뭐…내가 쓰는건데 개인적으로 쓰는거지 ㅡ,.ㅡ) 아까 젤 위에 가정을 할 때 k는 original message의 길이, n은 CRC정보가 첨부된 길이라고 했다. 즉, 항상 n>k 임을 알 수 있다. 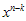 요거는 단지 u(x)의 k승수를 v(x)의 n승수로 맞춰주기 위해 곱해주는 것 일뿐~ 뭐 이것만 알면 아래에 SW구현 파트는 이해가 가능하다.
요거는 단지 u(x)의 k승수를 v(x)의 n승수로 맞춰주기 위해 곱해주는 것 일뿐~ 뭐 이것만 알면 아래에 SW구현 파트는 이해가 가능하다. 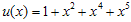 이다. g(x)의 경우 CRC-16으로 하기로하면
이다. g(x)의 경우 CRC-16으로 하기로하면 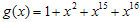 이 된다. 계산하면
이 된다. 계산하면 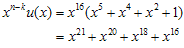
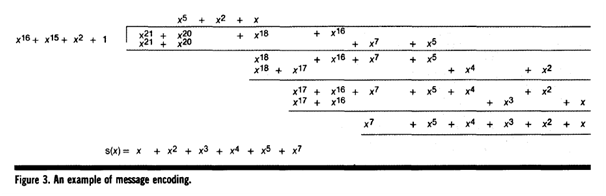
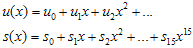
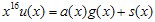
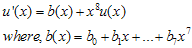
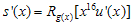
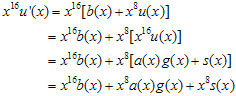
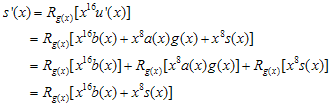
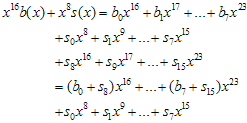
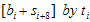 , i = 0,1, … , 7 로 변환시키면
, i = 0,1, … , 7 로 변환시키면 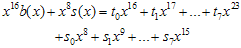
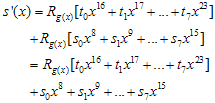
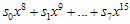 이것보다 큰 값이니까 나머지해봐야
이것보다 큰 값이니까 나머지해봐야 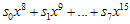 그대로 남는 것이고…자, 8비트 추가된 후의 나머지(CRC)값의 방정식이 구해졌다. 살펴보도록 하자.
그대로 남는 것이고…자, 8비트 추가된 후의 나머지(CRC)값의 방정식이 구해졌다. 살펴보도록 하자. 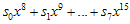 의미는 뭘까?
의미는 뭘까? 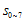 은 8비트 추가가 되기 전에 기존 CRC값의 high-order 8비트값이었다. 그런데 그게 단순히 8비트 right-shift 된 것이지. (x의 승수가 높을수록 low-order bit이다. 위에서 예제로 계산했던 것을 다시 살펴보자)
은 8비트 추가가 되기 전에 기존 CRC값의 high-order 8비트값이었다. 그런데 그게 단순히 8비트 right-shift 된 것이지. (x의 승수가 높을수록 low-order bit이다. 위에서 예제로 계산했던 것을 다시 살펴보자) 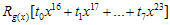 요녀석을 살펴보자. 여기서
요녀석을 살펴보자. 여기서 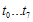 은 단순히 새로 추가된 8비트
은 단순히 새로 추가된 8비트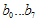 와 기존 u(x)의 하위16비트(CRC-16이니까)에서의 low-order 8bit인
와 기존 u(x)의 하위16비트(CRC-16이니까)에서의 low-order 8bit인 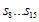 와의 합(XOR)이다. 결론은 꼭 1비트씩 할 필요없이 8비트씩 계산해도 괜찮다~라는것!!
와의 합(XOR)이다. 결론은 꼭 1비트씩 할 필요없이 8비트씩 계산해도 괜찮다~라는것!! 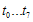 이 값은 8비트이므로 총 256개의 값을 가질 수 있고, 따라서
이 값은 8비트이므로 총 256개의 값을 가질 수 있고, 따라서 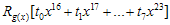 이 값은 미리계산 되어질 수 있다. (영어로 하자면 precomputable하다…정도? 모든 경우의 수를 다 계산해 놓는것) g(x)가 CRC-16의 경우
이 값은 미리계산 되어질 수 있다. (영어로 하자면 precomputable하다…정도? 모든 경우의 수를 다 계산해 놓는것) g(x)가 CRC-16의 경우 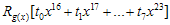 값은 최대 16비트값을 가지게 되므로 해당 테이블의 크기는 2byte * 256 = 512byte가 되겠다. CRC-8이라면 256byte를 가질 것이다. 계산 순서는 다음과 같다.
값은 최대 16비트값을 가지게 되므로 해당 테이블의 크기는 2byte * 256 = 512byte가 되겠다. CRC-8이라면 256byte를 가질 것이다. 계산 순서는 다음과 같다. 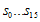 값이다)
값이다) 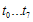 를 구한다. (
를 구한다. (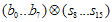 계산)
계산) 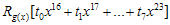 값을 CRC register에 XOR 연산을 한다.
값을 CRC register에 XOR 연산을 한다.  1_CRC.pdf
1_CRC.pdf